library(tidyverse)
library(flextable)
pisa <- read_csv("input/pisa_2022.csv")14 Analisis Varians Faktorial
14.1 Pengantar Analisis Varians Faktorial
| Growth Mindset | |||
|---|---|---|---|
| Iya | Tidak | ||
| Gender | Laki-laki | ||
| Perempuan |
Menggunakan R untuk menghitung rasio F. Contoh kali ini menggunakan data PISA 2022 dengan sampel tiga sekolah dengan sepuluh siswa di setiap sekolah seperti bab 15. Tujuan analisis faktorial ANOVA untuk melihat interaksi growth mindset terhadap siswa laki-laki dan perempuan.
pisa_gm <- pisa |>
select(CNTRYID, CNTSCHID, sex, growth, MATH) |>
mutate(gender = case_match(sex, 1 ~ "male", 0 ~ "female"),
gm = case_match(growth, 1 ~ "high", 0 ~ "low"))
View(pisa_gm)
pisa |> select(CNTRYID, CNTSCHID, sex, growth, MATH) |>
mutate(gender = case_match(sex, 1 ~ "male", 0 ~ "female"),
gm = case_match(growth, 1 ~ "high", 0 ~ "low")) |>
select(gender, gm, MATH) |>
group_by(gender, gm) |>
slice(1:10) |>
mutate(id = 1:n()) |>
ungroup() |>
pivot_wider(names_from = c(gender, gm), values_from = MATH)# A tibble: 10 × 5
id female_high female_low male_high male_low
<int> <dbl> <dbl> <dbl> <dbl>
1 1 466. 380. 327. 307.
2 2 497. 396. 346. 298.
3 3 463. 410. 325. 350.
4 4 442. 284. 400. 323.
5 5 313. 414. 364. 332.
6 6 473. 362. 367. 379.
7 7 457. 356. 389. 342.
8 8 388. 384. 366. 301.
9 9 348. 404. 287. 350.
10 10 429. 365. 328. 297.library(psych)
describeBy(pisa_gm$MATH, group = list(pisa_gm$gender, pisa_gm$gm))
Descriptive statistics by group
: female
: high
vars n mean sd median trimmed mad min max range skew
X1 1 240 408.59 69.75 411.11 409.79 74.18 237.29 580.7 343.41 -0.13
kurtosis se
X1 -0.56 4.5
------------------------------------------------------------
: male
: high
vars n mean sd median trimmed mad min max range skew
X1 1 220 395.54 69.16 381.95 391.86 67.78 258.13 632.92 374.79 0.49
kurtosis se
X1 -0.24 4.66
------------------------------------------------------------
: female
: low
vars n mean sd median trimmed mad min max range skew
X1 1 433 361.28 52.71 358.68 359.45 54.19 224.71 561.28 336.57 0.34
kurtosis se
X1 0 2.53
------------------------------------------------------------
: male
: low
vars n mean sd median trimmed mad min max range skew kurtosis
X1 1 404 355.43 58.29 347.46 350.89 54.61 188.95 542.1 353.15 0.67 0.43
se
X1 2.9options(contrasts = c("contr.helmert", "contr.poly"))
options("contrasts")$contrasts
[1] "contr.helmert" "contr.poly" m1 <- aov(MATH ~ gm + gender + gm*gender, data = pisa_gm)library(car)
Anova(m1, type = "III")Anova Table (Type III tests)
Response: MATH
Sum Sq Df F value Pr(>F)
(Intercept) 171368813 1 46362.4694 < 2e-16 ***
gm 566156 1 153.1689 < 2e-16 ***
gender 26456 1 7.1574 0.00756 **
gm:gender 3847 1 1.0409 0.30780
Residuals 4779294 1293
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1leveneTest(MATH ~ gm*gender, data = pisa_gm)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 3 13.514 1.099e-08 ***
1293
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1p <- pisa_gm |>
summarise(math = mean(MATH),
.by = c(gender, gm))
ggplot(p, aes(x = gender, y = math, group = gm, col = gm)) +
geom_point() +
geom_line() 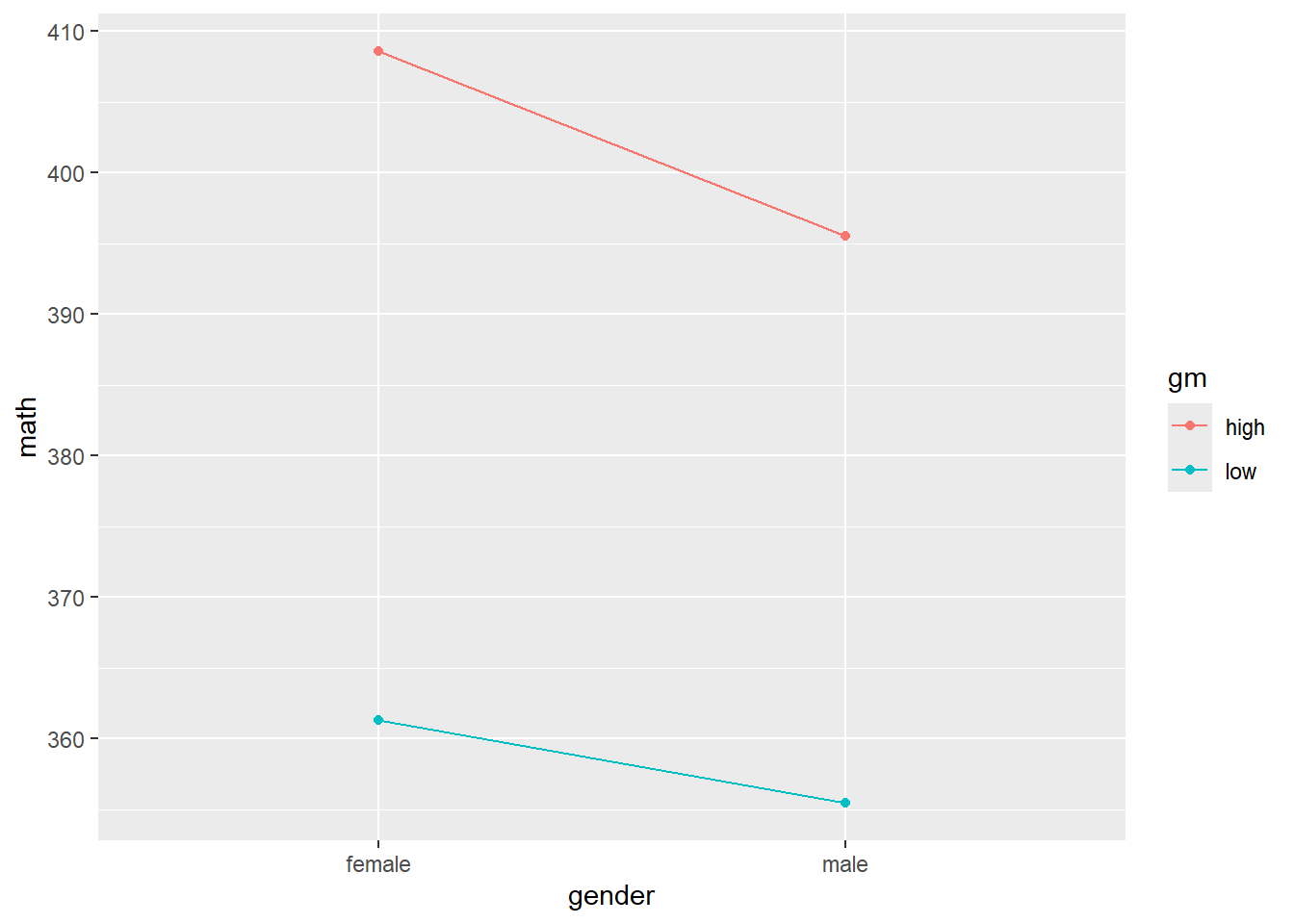
library(ggthemes)
ggplot(p, aes(x = gender, y = math, group = gm, col = gm)) +
geom_point() +
geom_line() +
labs(x = " ", y = "Rata-rata Skor Matematika", color = "Growth Mindset") +
scale_x_discrete(labels=c("Perempuan", "Laki-laki")) +
scale_color_discrete(labels = c("Tinggi", "Rendah")) +
theme(legend.position = "bottom") +
theme_hc()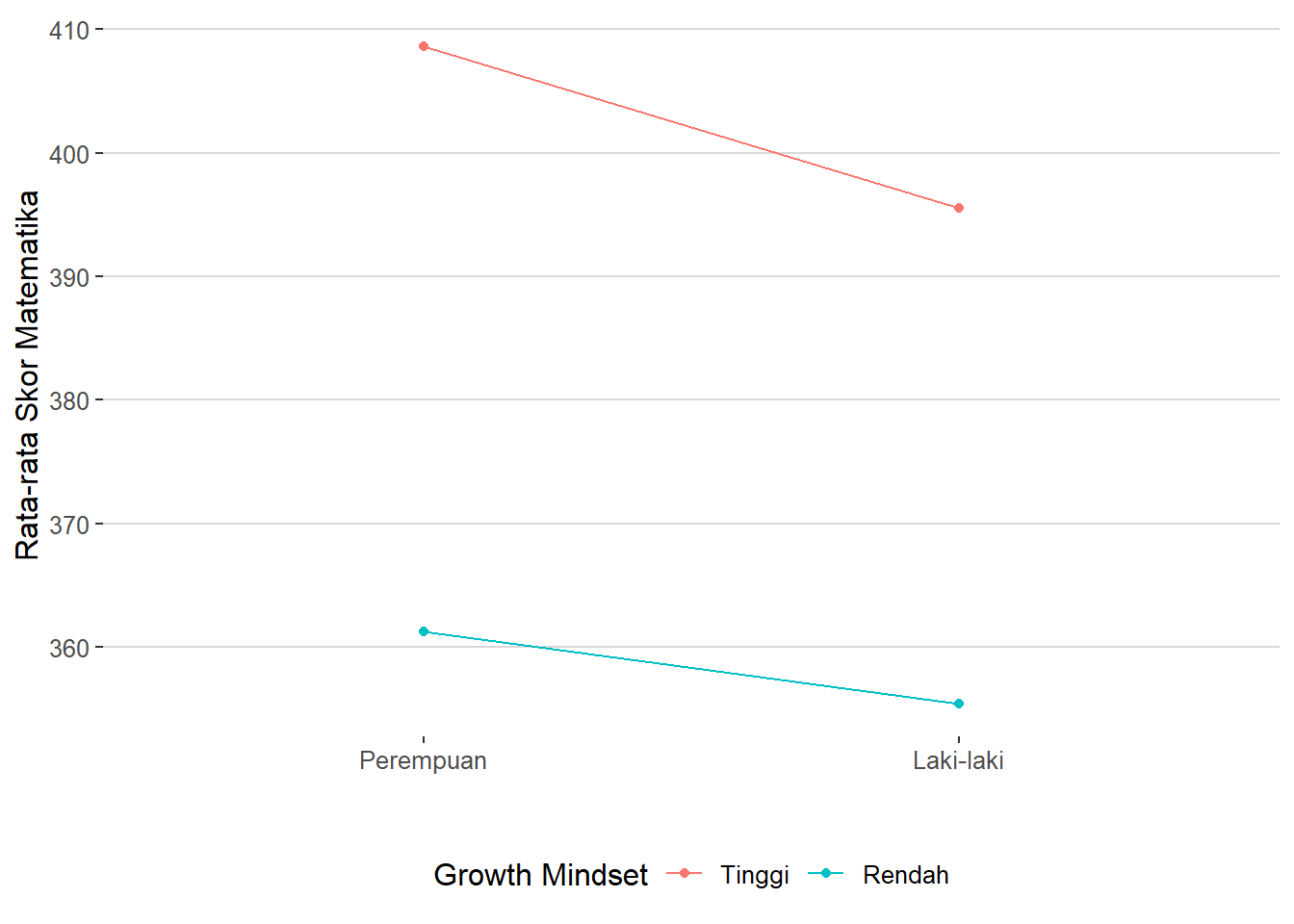
TukeyHSD(m1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = MATH ~ gm + gender + gm * gender, data = pisa_gm)
$gm
diff lwr upr p adj
low-high -43.88976 -50.81231 -36.96722 0
$gender
diff lwr upr p adj
male-female -8.39957 -15.02795 -1.771187 0.0130437
$`gm:gender`
diff lwr upr p adj
low:female-high:female -47.310383 -59.89601 -34.724755 0.0000000
high:male-high:female -13.051258 -27.64877 1.546257 0.0985550
low:male-high:female -53.155468 -65.90116 -40.409771 0.0000000
high:male-low:female 34.259126 21.31066 47.207590 0.0000000
low:male-low:female -5.845085 -16.66304 4.972867 0.5059009
low:male-high:male -40.104211 -53.20831 -27.000110 0.000000014.2 Menghitung Effect Size Faktorial ANOVA
Statistik faktorial ANOVA disebut dengan omega kuadrat yang diwakili oleh \(\omega^2\). Berikut adalah rumus statistik faktorial ANOVA:
\[ \omega^2 = \frac{SS_{between}-(df_{between groups})(MS_{within groups})}{MS_{within groups} + {SS_{total}}} \]
- \(\omega^2\) adalah nilai dari effect size,
- \(SS_{between}\) adalah jumlah kuadrat antar faktor,
- \(df_{between}\) adalah total derajat kebebasan,
- \(MS_{within}\) adalah rata-rata jumlah kuadrat dalam perlakuan \(SS_{within}/df_{within}\),
- \(SS_{total}\) adalah jumlah total kuadrat \((SS_{between} + SS_{within})\)
\[ \omega^2 = \frac{26456-(1)(3696.283)}{(3696.283) + (26456+4779294)} = 0.0047 \]