| 598.646 | 514.876 | 556.600 | 523.933 | 282.838 |
| 604.935 | 574.120 | 484.997 | 494.652 | 379.945 |
| 564.757 | 599.455 | 453.261 | 543.711 | 412.600 |
| 545.888 | 540.899 | 555.241 | 510.006 | 401.814 |
| 576.992 | 519.775 | 476.696 | 348.393 | 436.950 |
| 577.885 | 495.118 | 544.538 | 401.216 | 327.469 |
| 456.657 | 501.638 | 551.131 | 582.527 | 324.764 |
| 577.929 | 529.667 | 468.040 | 444.786 | 378.620 |
| 515.292 | 447.443 | 561.960 | 490.262 | 445.118 |
| 527.540 | 590.318 | 525.358 | 492.326 | 392.590 |
| 561.895 | 555.812 | 455.944 | 502.202 | 365.800 |
| 469.004 | 408.498 | 477.665 | 515.858 | 352.860 |
| 539.460 | 544.638 | 529.925 | 471.947 | 385.548 |
| 570.763 | 457.881 | 471.790 | 621.813 | 414.409 |
| 546.095 | 583.233 | 430.900 | 395.003 | 347.514 |
| 579.563 | 520.247 | 585.657 | 536.258 | 378.472 |
| 489.969 | 530.644 | 495.572 | 522.439 | 479.327 |
| 635.422 | 533.546 | 483.036 | 541.856 | 428.055 |
| 464.534 | 529.073 | 500.343 | 293.051 | 396.411 |
| 567.682 | 611.659 | 475.751 | 278.139 | 334.526 |
5 Membuat Grafik
5.1 Mengapa Mengilustrasikan Data?
5.2 Sepuluh Cara Membuat Grafik yang Keren
Cara ini berlaku saat membuat ilustrasi dengan tangan maupun menggunakan bantuan komputer.
5.3 Membuat Distribusi Frekuensi
Distribusi frekuensi adalah sebuah metode penghitungan dan merepresentasikan seberapa sering skor tertentu muncul. Dalam pembuatan distribusi frekuensi, skor biasanya dikelompokkan ke dalam interval kelas, atau rentang angka.
Berikut ini adalah 50 skor pada tes pemahaman membaca yang menjadi dasar distribusi frekuensi:
Inilah distribusi frekuensi yang menampilkan jumlah frekuensi setiap rentang skor:
q1 q2 q3 q4
1 17 32 47 4gt(tbl_df) |>
cols_label(kelas = "Interval Kelas", frekuensi = "Frekuensi")| Interval Kelas | Frekuensi |
|---|---|
| < 400 | 17 |
| 400 - 500 | 32 |
| 500 - 600 | 47 |
| > 600 | 4 |
5.3.1 Interval yang Paling Berkelas
Berikut ini aturan yang perlu diikuti dalam membuat sebuah interval kelas, terlepas dari ukuran nilai pada data set yang digunakan.
5.4 Membuat Histogram
Membuat histogram sederhana menggunakan R. Disini kita akan menggunakan data PISA dengan variabel math yang mendeskripsikan rata-rata skor matematika.
math <- pisa[1:100, ]hist(math)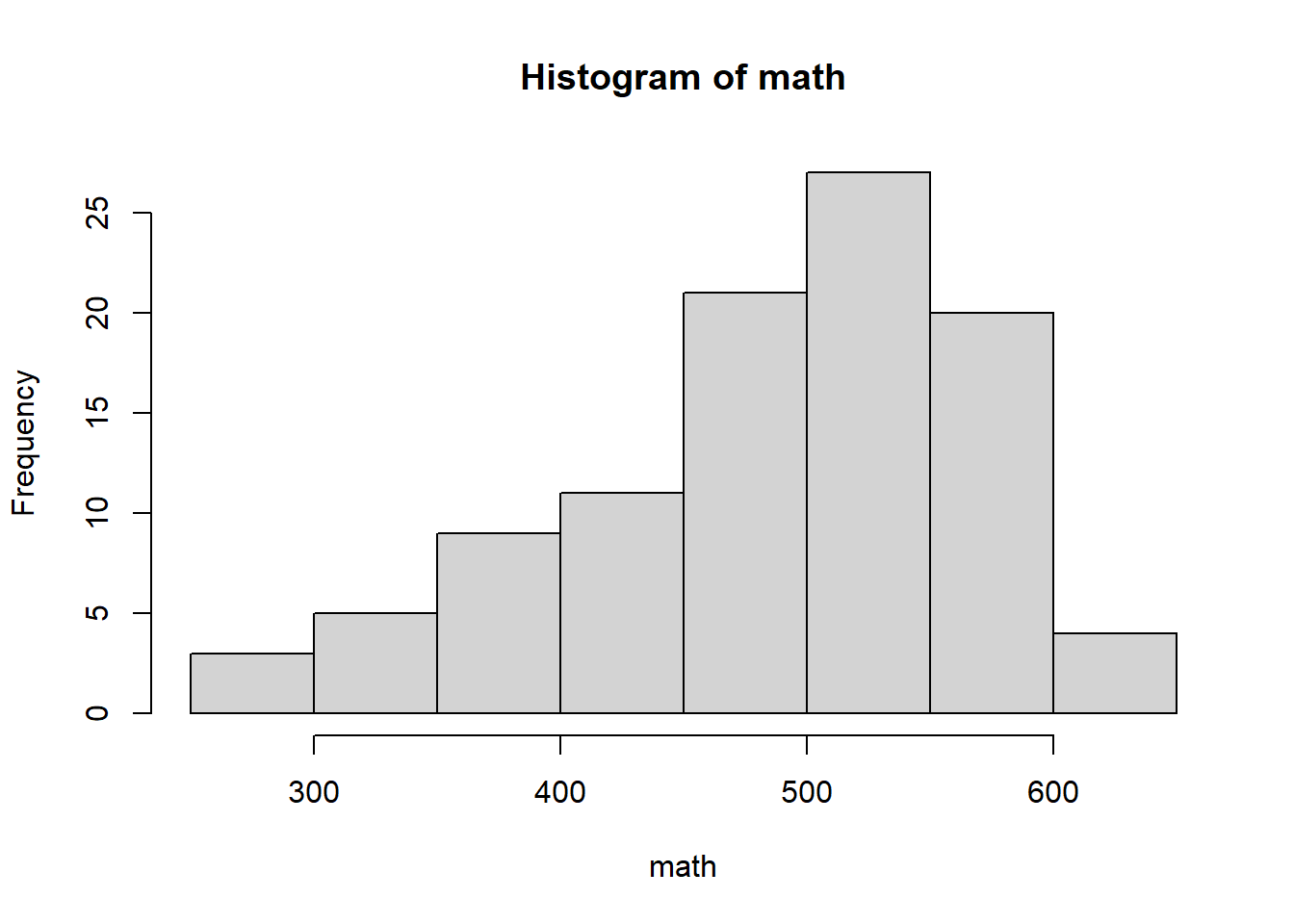
hist(math, breaks = 4)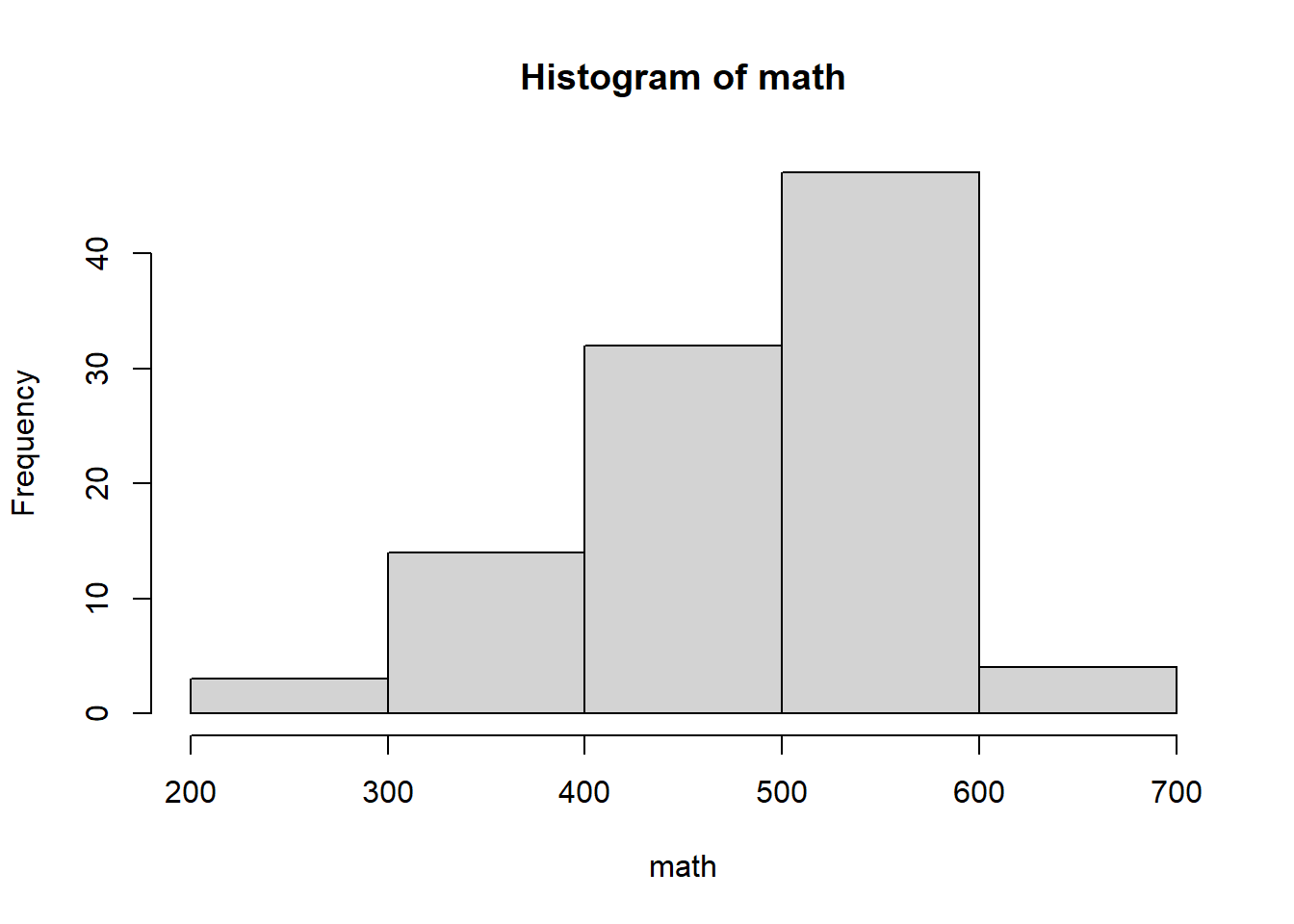
hist(math, probability = TRUE)
lines(density(math))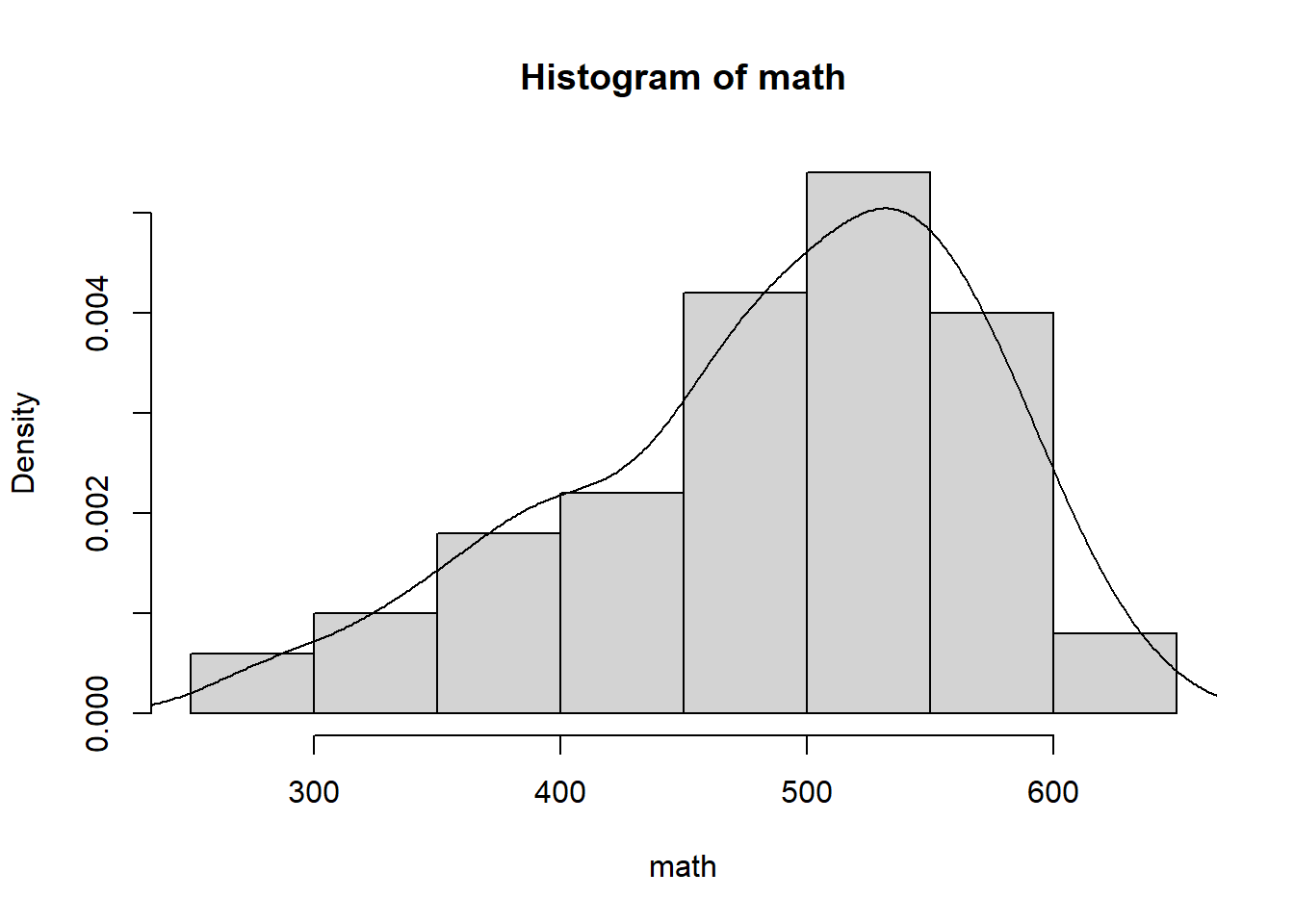
5.5 Akumulasi Frekuensi
Distribusi frekuensi kumulatif didasarkan pada data yang sama dengan distribusi frekuensi, namun dengan tambahan kolom (Frekuensi Kumulatif), seperti yang ditunjukkan di bawah ini.
gt(tbl_kum) |>
cols_label(kelas = "Interval Kelas",
frekuensi = "Frekuensi",
frek_kum = "Frekuensi Kumulatif")| Interval Kelas | Frekuensi | Frekuensi Kumulatif |
|---|---|---|
| < 400 | 17 | 100 |
| 400 - 500 | 32 | 83 |
| 500 - 600 | 47 | 51 |
| > 600 | 4 | 4 |
5.6 Cara Keren Lainnya Untuk Memetakan Data
5.6.1 Bar Charts
Diagram batang atau kolom baik digunakan untuk membandingkan frekuensi kategori yang berbeda. Kategori disusun secara horizontal pada sumbu x, dan nilai ditampilkan secara vertikal pada sumbu y.
Ini adalah contoh penggunaan diagram batang atau kolom: 1. Jumlah perserta dalam berbagai aktivitas olahraga air 2. Penjualan dari tiga jenis produk yang berbeda 3. Jumlah anak di masing-masing dari enam kelas yang berbeda
5.6.2 Column Charts
Bagan kolom identik dengan bagan batang, tetapi dalam bagan ini, kategori disusun pada sumbu y (yang merupakan sumbu vertikal), dan nilai ditampilkan pada sumbu x (sumbu horizontal).
5.6.3 Line Charts
Diagram garis digunakan untuk menunjukkan tren dalam data pada interval yang sama. Contohnya:
- Jumlah kasus mononukleosis (mono) per musim di antara mahasiswa di tiga universitas negeri
- Penjualan mainan untuk perusahaan T&K selama empat kuartal
- Jumlah pelancong yang menggunakan dua maskapai penerbangan yang berbeda untuk setiap kuartal
5.7 Menggunakan R Untuk Mengilustrasikan Data
Mari kita praktikan langkah-langkah membuat beberapa diagram. Langkah pertama, membaca data set. Disini, data yang digunakan adalah data PISA 2022 berbentuk sampel (pisa.csv).
pisa <- read.csv("data_name.csv")
View(pisa)Kita akan membuat kembali histogram dengan pisa$math. Setelah membuat data set, kita akan kembali ke pengukuran memusat dan variabilitas. Untuk melakukannya, kita akan menggunakan funsgi yang disebut summary().
- Buat histogram.
- Jalankan fungsi summary pada variabel math dalam objek
pisa. - Jalankan fungsi
sd()pada variabel math dalam objekpisa. - Temukan statistik berikut ini pada histogram:
- Mean
- Median
- -1 standard deviation
- +1 standard deviation
Berikut ini syntax untuk membuat histogram dan menampilkan statistik yang diinginkan:
library(ggplot2)
pisa |> ggplot(aes(math)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.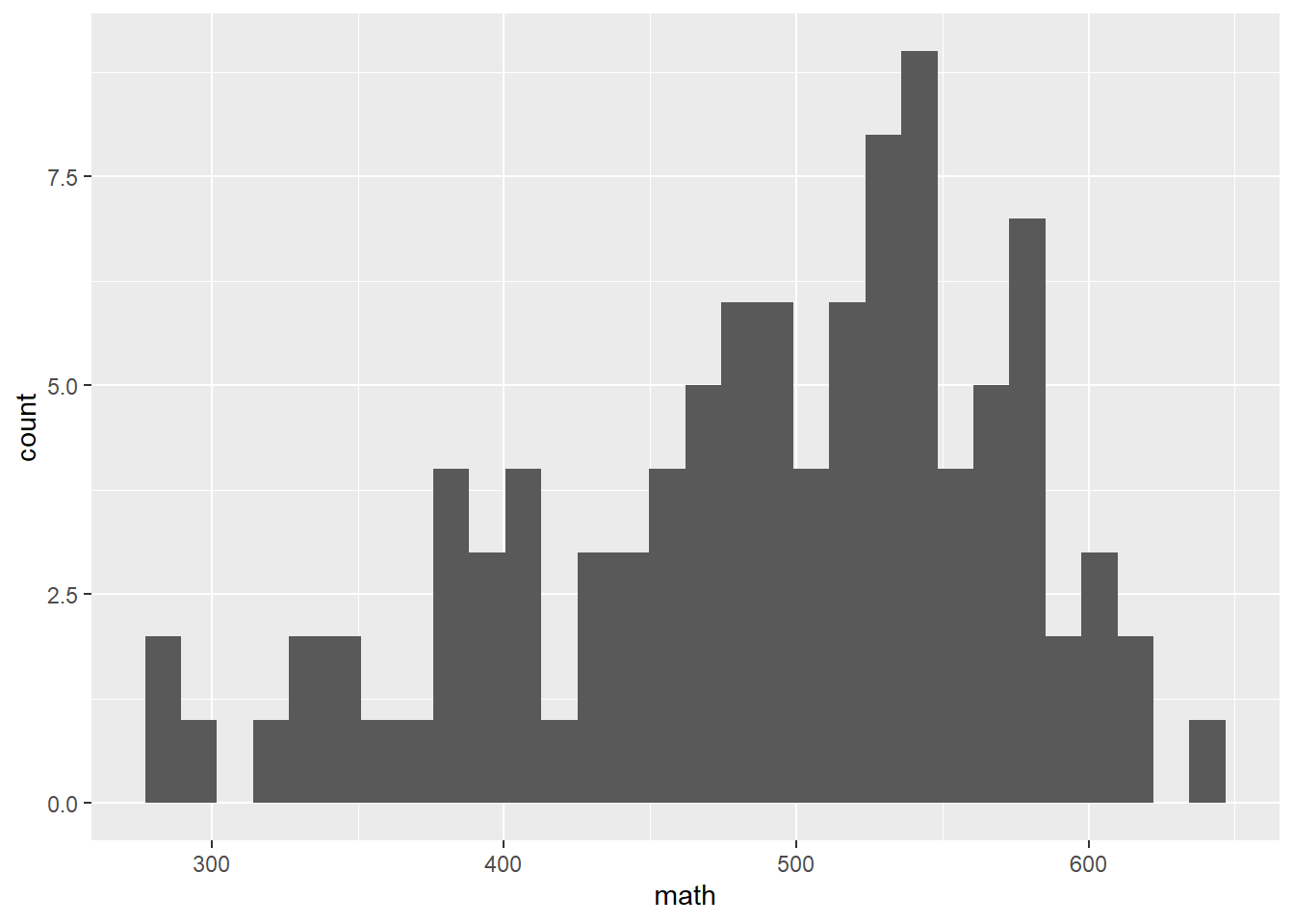
pisa |>
summarise(min = min(math),
median = median(math),
mean = mean(math),
max = max(math)) min median mean max
1 278.139 500.9905 488.1986 635.422pisa |>
summarise(sd = sd(math)) sd
1 81.9186